A Sandbox Is Not an Agent Runtime
Code is still one of the central assets of a company. AI agents don’t make it cheap. They make it easier to produce more of it, which means they also make it easier to produce more mistakes, more migrations, more half-finished branches, and more changes that someone has to understand. That is why architecture is still the product, and agents make that more true, not less.
The current agent workflow still depends on a developer sitting beside the tool. The agent reads files, edits code, runs tests, gets stuck, asks for help, and the developer keeps steering. That can work, but steering is work. You keep the task in your head, watch the tool, interpret failures, approve commands, stop it from wandering, and then review the diff at the end.
For small work, that can still be a win. For a one-off bug fix, a test, or a small refactor, the loop is acceptable. But once the work becomes an enterprise migration, a repo-wide cleanup, a dependency upgrade across services, or a backlog of issues that all look agent-solvable, the human-in-the-loop model becomes the bottleneck.
the attention bottleneck
The problem is not that agents can’t write code. They can. The problem is that every useful agent session consumes human attention while it runs.
You don’t feel this when one agent is working on one task. You feel it when there are ten obvious tasks an agent could do, and each one still requires you to start a session, watch for failures, answer permission prompts, nudge it back into scope, and decide when the result is good enough.
At that point the developer isn’t coding by hand anymore, but they’re still renting their attention to the agent. The productivity gain becomes blurry because the agent removed typing but kept supervision.
This is why agents have to move away from the developer’s terminal. They need to run in headless environments with a filesystem, a shell, git, tests, browsers, package managers, and enough state to continue for longer than one interactive session. If the task needs a browser, the browser should be in the environment. If it needs package installs, test runners, docs, or a dev server, those should be in the environment too. The agent should be able to pick up work, make changes, verify those changes, open pull requests, and stop at clear boundaries.
the cloud runtime shift
This is where the market is moving. GitHub Copilot coding agent is the easiest version to understand because the agent runs inside an ephemeral GitHub Actions-powered development environment. The work leaves the local terminal and moves into infrastructure that can be created for a task.
The same shape shows up elsewhere. E2B provides cloud sandboxes with terminal, filesystem, git, and prebuilt coding-agent templates. Daytona frames itself as secure elastic infrastructure for running AI-generated code. Runloop calls its environments Devboxes, virtual workstations where agents can pull repos, run code, browse, and persist or resume state. Docker Sandboxes is moving the same idea into isolated microVMs with their own Docker daemon, filesystem, and network.
All of them are circling the same point: the useful unit is not a chat window. The useful unit is an isolated computer that an agent can operate.
But a sandbox is only the place where the agent runs. It does not decide what the agent should do, when it should stop, how it should recover, which credentials it should see, which network destinations it can reach, how a human approves a risky command, or how the organization audits what happened later.
The missing layer is the runtime around the agent. Sometimes that runtime talks directly to a model through an SDK. Sometimes it starts an existing coding agent like OpenCode, OpenHands, Claude Code, or Codex and lets that agent own the model loop. The important part is not who makes the model call. The important part is who owns the work lifecycle.
That lifecycle layer turns “agent with shell access” into “safe worker on this repository.” It knows how to clone the repo, choose the branch, read the task, start the right agent, expose the workspace, stream events, checkpoint progress, request approvals, collect logs, create the PR, and clean up the environment.
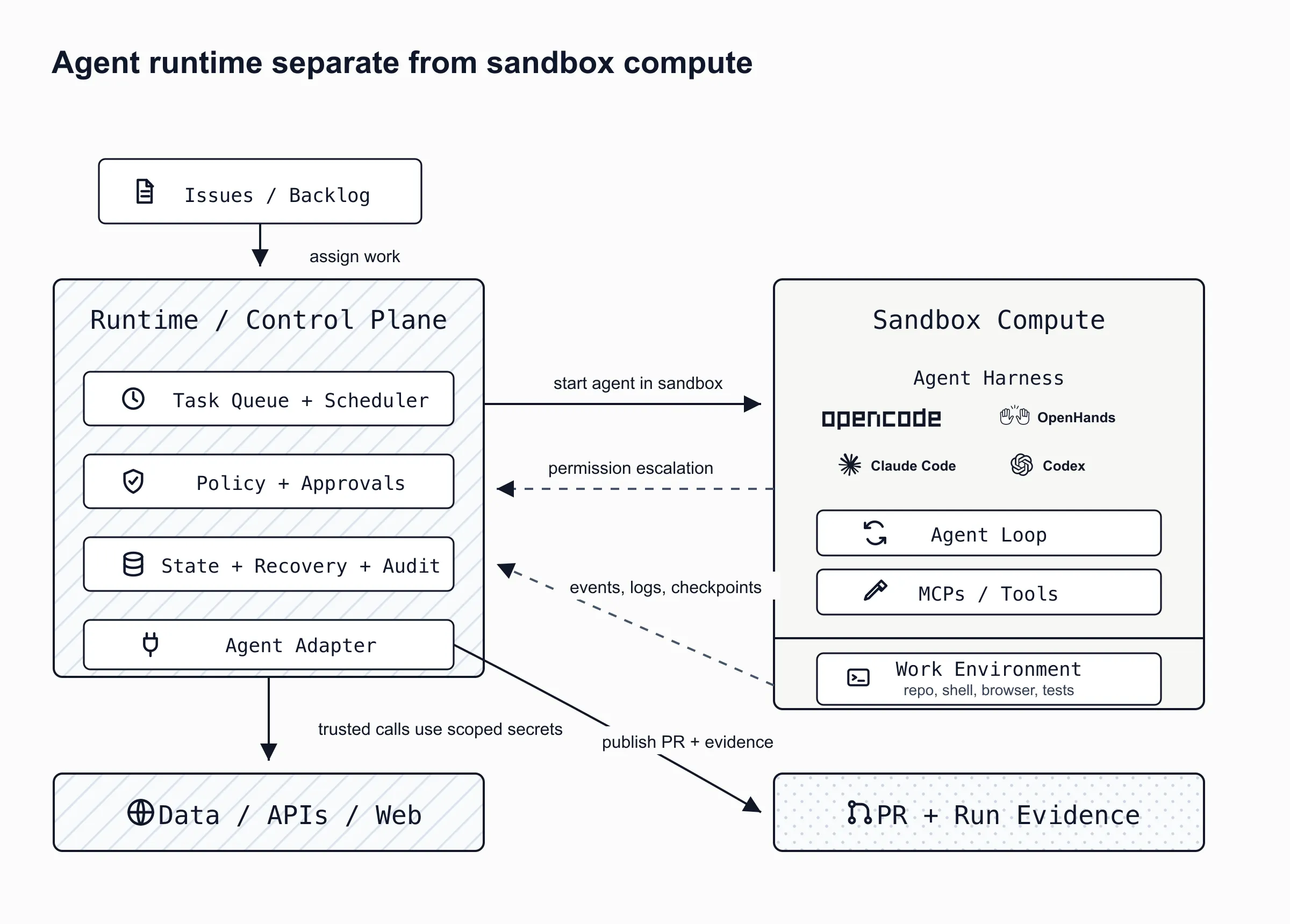
Without that layer, you don’t have an autonomous development system. You have a VM, an agent binary, and an API key.
what I saw testing this
I ran into this split directly while testing the current options.
OpenCode inside E2B looked promising because E2B has a prebuilt OpenCode template and OpenCode supports OpenAI-compatible providers. The sandbox provisioned, the newer OpenCode version installed, and server mode worked once well enough to create a file through a prompt. But opencode run hung, and the path didn’t feel reliable enough to build a real workflow on top of it.
Daytona showed the same problem from another angle. The sandbox came up. OpenCode could be installed. The server listened on the exposed port. The client could create a session. Then the prompt hung until timeout. The infrastructure worked, but the full agent path didn’t.
OpenHands showed a different boundary. The OpenAI-compatible endpoint was not the hard part in my test. The harder question was whether the same setup could become a reliable cloud worker. Current OpenHands V1 talks about Docker, process, and remote sandboxes, while the older E2B and Daytona integrations sit in the legacy runtime path. That does not make OpenHands bad. It just shows that endpoint compatibility and cloud-runtime reliability are different claims.
The OpenAI Agents SDK sits in another category again. It gives you orchestration primitives, tools, traces, handoffs, and a shell tool interface. The shell tool docs are explicit that command execution still needs a sandbox, minimum privileges, filesystem allowlists, and audit logging. The SDK is not the worker by itself. It is a way to build the worker if you bring the executor, the sandbox, and the policies.
This is why OpenAI-compatible endpoint support is not the whole problem. I already hit this split while looking at AI coding agents and the cloud provider gap, and again while trying to make Claude Code work with any model. Model compatibility gets tokens flowing. It does not guarantee tool-call behavior, streaming shape, usage accounting, long-running session state, approval semantics, or recovery after a crash. A provider can be OpenAI-compatible at the chat-completions level and still fail once a coding agent starts doing multi-step tool work.
the agent os idea
People are starting to call this an Agent OS. The phrase is loose, but the useful version is concrete.
Builder Methods Agent OS uses the term for spec-driven development: project standards, product plans, specs, task breakdowns, and commands that coding agents can follow inside tools like Claude Code, Cursor, and Codex. That is useful because it gives the agent written standards instead of leaving the codebase rules inside a developer’s head. It is closer to “development process as code” than infrastructure.
PwC’s agent OS uses the term at the enterprise workflow layer: connecting agents from different platforms into governed business workflows across systems like GitHub, Salesforce, SAP, Workday, cloud providers, and model vendors. That is closer to enterprise orchestration.
Dreamer uses the term in a more personal-computing way. The Sidekick sits at the center and mediates what agents can do for the user. Agents work through it, permissions flow through it, and user memory lives there. That is closer to an agent-mediated app platform.
For coding agents, the research version is closer. The TopoClaw paper describes Agent OS as a kernel-like layer for lifecycle management, memory, scheduling, and access control. The Crab paper names the exact failure mode in agent sandboxes: agent frameworks see tool calls but not their OS effects, while the OS sees filesystem and process changes but not the agent turn that caused them.
That is the gap. The coding agent changes files, spawns processes, installs packages, and edits state across a sandbox. The agent sees its conversation, tool results, and local context. The machine sees process and filesystem effects. The runtime has to connect both views.
what the runtime should look like
For coding agents, the practical version of an Agent OS is an agent runtime with a control plane.
The control plane should be the source of truth. It owns the task id, repository, branch, sandbox id, assigned agent, status, checkpoints, approvals, logs, and final output. Git remains the source of truth for code. The database or durable store becomes the source of truth for the agent’s work lifecycle.
A task enters from GitHub, Linear, Jira, or an internal backlog. The runtime creates one isolated sandbox for that task, checks out the repo, creates a branch with a predictable name, injects only the credentials needed for that task, and starts the selected agent or agent adapter.
The agent can run inside the sandbox or be driven from beside it, but the runtime has to own the outer loop. It sends the task to the agent, exposes the working environment, records agent events, captures command output, watches file changes, runs verification, and writes checkpoints. If the agent process dies, the control plane should know where it stopped. If the sandbox dies, the runtime should recreate it, restore the branch, reload the task state, and continue from the last safe checkpoint.
Checkpointing cannot be chat history only. If the agent changed three files, installed a dependency, generated a cache, and left a dev server running, the recovery system has to know which of those effects matter. That is why the agent runtime has to observe both the agent loop and the sandbox state.
Permissions need to sit in the middle of every risky action. Reading files, editing the working branch, and running tests can be allowed by default. Installing new packages, opening outbound network access, reading secrets, pushing branches, changing deployment config, or touching production systems should go through policy. Some policies can be automatic. Some need human approval.
Credentials should be short-lived and scoped. The agent should not run with a developer’s personal access token. It should get a worker identity that can do exactly what the task requires: clone this repo, push this branch, open this PR, read this package registry, call this internal API. This is the runtime version of the AI trust gap: if the agent does something wrong, the audit trail should show which identity acted and under which task.
Network access should also be explicit. Most coding tasks do not need the whole internet. Some need GitHub and package registries. Some need documentation sites. Some need internal services. The sandbox should enforce that allowlist instead of hoping the prompt keeps the agent disciplined.
The output should be boring: a branch, a PR, a test report, a structured run log, and a list of approvals or denied actions. If the task cannot be completed, the output should be a handoff with what was tried, what failed, and what state the repo is in.
That is the runtime. Not more agents. Not a bigger prompt. A durable control plane around one agent doing one task in one sandbox with a clear lifecycle and a complete working environment.
where the market is still split
The solved parts are scattered. Cloud sandboxes exist. Coding agents exist. Agent SDKs exist. GitHub-hosted coding agents exist. Vendor-managed agents exist. What is still immature is the clean, agent-aware, cloud-hosted runtime that can run a real coding agent against a real repository, configure the endpoint it needs, and give you production controls.
The more interesting platforms are starting to acknowledge this. Sandbox0 separates “agent in sandbox” from “sandbox as tool.” That distinction matters. Sometimes the agent process itself should live inside the workspace, because coding agents expect local files, browser state, home-directory state, shell commands, and long-lived process state. Other times the agent loop should live in a control plane, and the sandbox should only be claimed when the agent needs to execute code.
OpenEnv’s opencode_env is interesting for the same reason, even though it comes from a research and training angle. It frames OpenCode as running inside an isolated E2B sandbox against any OpenAI-compatible endpoint. That is closer to the thing I was trying to observe: not just a sandbox, and not just a model endpoint, but a wrapped coding-agent environment that can be driven programmatically.
The strongest commercial systems solve the problem by controlling more of the stack. GitHub controls the issue, repo, branch, Actions environment, and PR surface. OpenAI Codex Cloud controls the agent and managed environment. Devin-style systems control the workspace and agent loop. That makes them more reliable, but also more closed.
The open question is whether the open ecosystem can produce the same reliability without locking the model, sandbox, repo host, and harness into one vendor.
the useful first version
Most projects should start smaller than the demos.
One repo. One task queue. One sandbox per task. One branch per task. One agent. One PR. One approval path for privileged actions. One audit trail. No team of agents until the single-agent lifecycle is boring.
That first version should stop at a pull request. Deployment orchestration is a different risk class. Once the system can repeatedly create good branches, recover after failure, explain what happened, and ask for approvals at the right boundary, then it can move closer to deployment.
This also changes how to judge agent-orchestration projects. I already wrote that more agents is not all you need. This is the operational version of that claim. The question is not whether a system can spawn multiple agents. More agents is cheap. The question is whether it can run one agent safely for a long time, recover it after failure, explain what it did, and stop it before it crosses a boundary.
The direction is clear. Coding agents are moving from local assistants to cloud workers. The hard part is no longer proving that an agent can edit code. That has been proven. The hard part is making the environment around the agent boring enough that a company can let it run while nobody is staring at the terminal.